Part 3 - Application Troubles in the Cloud (Symptom: Application Functional Problems)
Overview
Introduction
I have recently supported a customer to deploy numerous applications over multiple OpenShift clusters running on top of hundreds of worker nodes, using external storage infrastructure for persistence and Red Hat Service Mesh (OSSM) for encryption, authentication and traffic management.
The method to deliver in this environment did not differ too much from delivering the applications in any other environment, with automation involved throughout, however when an application issue was reported for many of the platform maintenance team members it was not possible to hone in quickly on the area they should focus on. It was not immediately obvious what information would assist in the problem identification and resolution or where from and how to collect them.
In Part 1 and Part 2 blog posts we looked at the cluster health and state as well as service mesh state in order to resolve POD startup failures. In this third blog we will focus on the Application Failures that may be caused by Service Mesh setup, cluster configuration and health or simply by Application functional failures.
- Part 1 - Application Troubles in the Cloud (Symptom: Kubernetes POD Failures/Restarts)
- Part 2 - Application Troubles in the Cloud (Symptom: Performance Problems whilst part of a Service Mesh)
- Part 3 - Application Troubles in the Cloud (Symptom: Application Functional Issues)
Causes for Application Functional Failures
The third symptom the platform maintenance personnel and users came up against were application functional behavioral failures related. The causes of these failures were not easy to understand if they were coding errors or environmental problems but the result was that responses were incorrect or completely failed. Troubleshooting such issues we will focus on three possible causes :
- Cause 1: Application Logic Failures
- Cause 2: Application Configuration Errors
- Cause 3: Incorrect Application Environment Configuration
Below we present one by one the causes along with the possible areas to focus for each, as well as the information which should be gathered and looked upon.
Cause 1 - Application Logic Failures
During any application failure if the client application receives execution errors the immediate focus area should be what was the targeted POD’s behavior at the time. Since we are running on top of an OpenShift (OCP) (or Kubernetes) containers cluster, checking the application logs for errors would be the first action we would take. In addition, Deployment (or DeploymentConfig) details as present in the cluster would need to be reviewed to ensure the expected versions are deployed. If it is identified that a non-expected version exists the problem could be either in the GitOps/CICD automation or due to a mis-expectation from the user side of functionality that is not yet released. Since the workloads are also part of the Service Mesh KIALI UI offers the ability to view a combination of the app and proxy container logs for the POD under investigation.
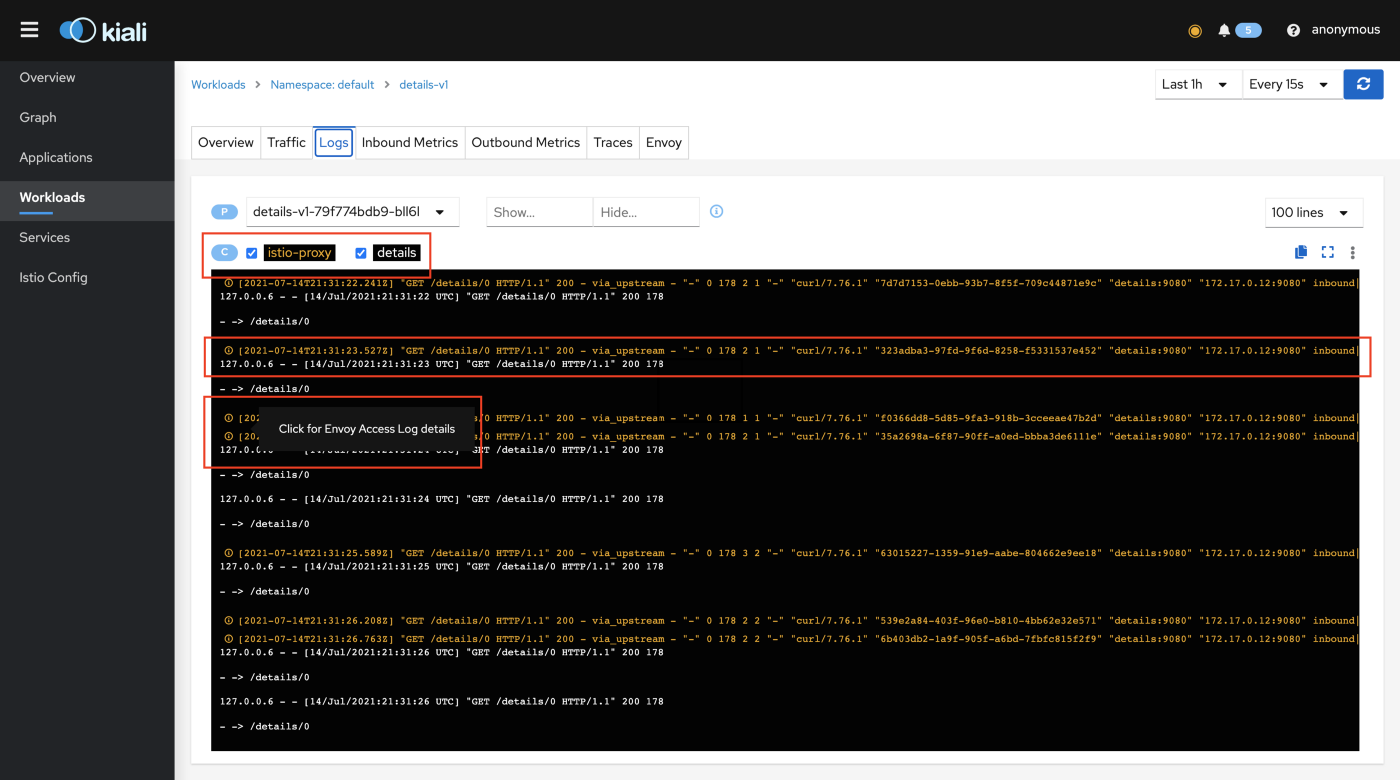
If the problem is not as a total execution failure but rather an execution logic issue again the the application’s logs (with increased logging level) can assist identifying the cause. If it is not immediately obvious which POD to look at the the Service Mesh’s Observability and tracing of the flow of requests to/from the component could pinpoint to a failing component.
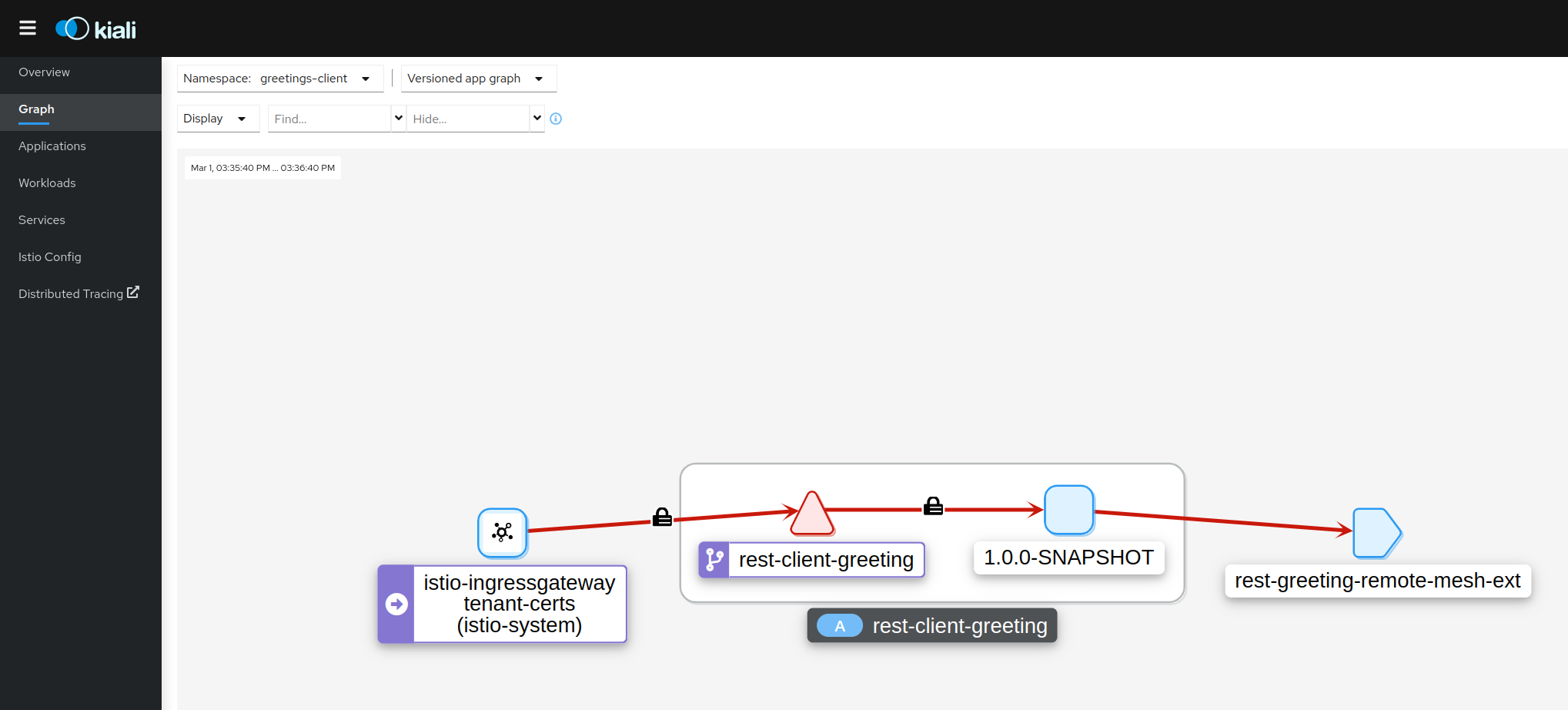
Cause 2 - Application Configuration Errors
Application misconfigurations are very common causes of execution/logic failures. In a cloud based environment where these configurations can be distributed in it is important to be aware where to find them:
- code included files (less common or recommended)
configMaporsecretOCP resourcesDeployment(orDeploymentConfig) Environment VariablesPODarguments
Verifying the application configuration expectations per environment of the above would be a highly recommended action. In addition, the application team is expected to provide description of the internal or externalized configurations.
In particular, as we mentioned in the first blog the Deployment configuration can be quite complex and hence look once more what could be the Deployment Configuration related application functionality failures.
Cause 3 - Incorrect Application Environment Configuration
The final type of configurations which can be causing the functionality mishaps can be provided by the environment itself. The incorrect application environment configurations can be located at:
StorageClassun-availability to store application configs- Service Mesh configurations for traffic management:
Gateway,DestinationRules,VirtualService,ServiceEntryaffecting the flow of incoming or outgoing requests - Service Mesh control plane health such as failed ingress/egress or istiod pods
- Service Mesh network policies and configurations as defined by the SMMR and SMM resources
- Availability of dependencies such as storage resources, database, kafka partitions etc.
All of the above can alter the behavior of microservices and cause an unexpected output.
Conclusion
Application functionality failures do not only occur because of incorrect coding and in a cloud based environment many layers of participating components (from the service mesh to the container platform, external storage etc.) can contain misconfigurations. The result of these misconfigurations could potentially result in execution or logic failures and it is important that the causes are inspected to reach a safe conclusion on the required action to rectify those.
The 3 blogs together provide an insight to the possible causes of symptoms of failures in the a containerized environment and the possible actions to review and resolve these causes. The combined resources around exploring troubleshooting around this symptom can also be found at Application (in Service Mesh) performance problems.
Posts in this Series
- Part 3 - Application Troubles in the Cloud (Symptom: Application Functional Problems)
- Part 2 - Application Troubles in the Cloud (Symptom: Performance Problems whilst part of a Service Mesh)
- Part 1 - Application Troubles in the Cloud (Symptom: Kubernetes POD Failures or often Restarts)